

Muchas veces los compañeros que mantienen los sitios web de centros (o los suyos propios) me han hecho la misma pregunta: “¿cómo puedo convertir un sitio web estático en un blog, o en un sitio web dinámico?”. Sin ánimo de mostrarme sarcástico, sino más bien realista, casi siempre he contestado algo muy parecido: “con mucho trabajo, paciencia, y una tediosa repetición de uno de los rudimentos informáticos que se aprenden en la primera hora del primer curso de formación sobre Informática: Control + C (copiar) –> Control + V (pegar)”.
Creo que mi respuesta sigue siendo válida en términos generales, pero al menos para los sitios web realizados con WordPress existen herramientas que pueden aligerar tan pesadísima tarea. Me refiero, en concreto, al plugin Import HTML Pages, con el que me encontré hace poco por casualidad, mientras preparaba el artículo Más sobre taxonomías y tipos de contenido personalizados: plugins para taxonomías. Esta extensión permite “leer” archivos HTML individuales (no hay límite de cantidad, aunque cuanto más archivos se importen más estrés sufrirá el servidor), y convertirlos en entradas de un blog o en páginas estáticas, con el ahorro consiguiente de tiempo y esfuerzo. A continuación explicaré con detalle el funcionamiento del plugin y ofreceré algunos consejos sobre cómo organizar el proceso de importación y preparar los archivos HTML para obtener resultados óptimos.
Para empezar, conviene saber que el importador sólo “lee” el código HTML de los archivos, y no las imágenes, las hojas de estilo u otros archivos enlazados mediante hipervínculos. Por tanto, hay que ser consciente de que en el proceso de importación se perderán los enlaces a dichos elementos, a no ser que en el blog se reproduzca la misma estructura de enlaces que en el sitio original, circunstancia harto improbable.
En segundo lugar, es aconsejable que la estructura del blog esté definida antes de comenzar con la importación. En efecto, el plugin sólo puede asignar las entradas a categorías o taxonomías personalizadas que ya existan, por lo que es mejor haber definido éstas antes de comenzar el proceso de importación. Es cierto que la adscripción de entradas a sus respectivas categorías siempre se puede realizar a posteriori, pero ello supone una carga de trabajo añadida de la que se puede prescindir siguiendo el consejo que acabo de dar.
Por otra parte, es necesario tener en cuenta que cada vez que se pone en funcionamiento el importador, éste asignará todos los archivos HTML a la misma categoría. Por tanto, si se quiere importar contenido para varias categorías diferentes, hay que realizar una importación selectiva por lotes, lo que obliga a una preparación previa del material que se va a importar.
El factor que más influye en el acabado final del contenido importado es la calidad del material previo. En efecto, si el código HTML está bien organizado y formateado, las posibilidades de éxito aumentarán y disminuirá el tiempo invertido en los inevitables retoques posteriores. Por el contrario, si el código HTML tiene fallos de etiquetado o/y organización, los resultados serán imprevisibles, y obligarán a un ímprobo trabajo de afinamiento y depuración. Es preciso, por tanto, un cuidadoso esfuerzo de limpieza del código HTML original. A lo largo de este artículo daré algunos consejos al respecto.
A continuación explicaré brevemente las principales características funcionales del plugin, ilustradas con las correspondientes capturas de pantalla.
1. Selección de archivos para importar
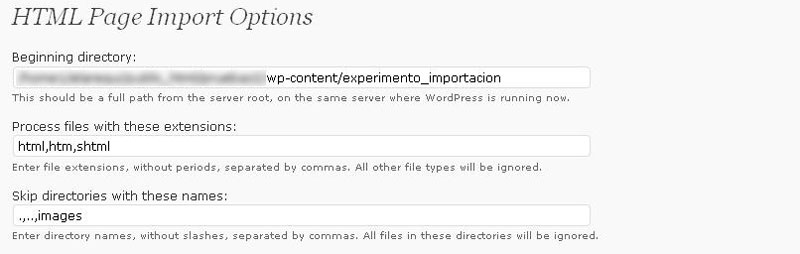
La extensión sólo puede funcionar si los archivos HTML se encuentran en una ubicación a la que pueda acceder WordPress. Por tanto, habrá que transferir por FTP dichos archivos a una ruta accesible por el blog. En la figura 1, bajo el epígrafe Beginning directory, puede verse la ruta que he definido para uno de mis blogs de pruebas.
El importador puede manejar cualquier fichero HTML, independientemente de su extensión. En la figura 1 aparecen las extensiones por defecto que se incluyen bajo el campo Process files with these extensions (mis pruebas se han realizado sobre archivos con la extensión .shtml), pero también son posible otras, siempre que se trate de archivos estáticos, cuyo contenido no dependa de la ejecución dinámica de scripts. Por poner un ejemplo, se podrían importar archivos PHP o ASP o de cualquier otro lenguaje de programación legible por el plugin, pero sólo se importará la parte estática de dichos archivos, no aquel contenido que se genere de forma dinámica en el servidor cuando se ejecuta el código correspondiente. También se pueden elegir aquellos directorios que serán ignorados por el importador, para lo cual hay que rellenar el campo Skip directories with these names con los valores necesarios.
2. Selección del contenido
Tal como puede observarse en la figura 2, en el epígrafe Select content by, el plugin permite importar contenido basándose en la selección por etiquetas HMTL o por regiones de plantilla de Dreamweaver. Naturalmente sería preferible la segunda opción, pero estoy seguro de que la mayoría de los usuarios que se enfrentan con el problema de pasar sus archivos estáticos a un sistema dinámico no habrán editado sus ficheros con el programa de Adobe o, si lo han hecho, no habrán definido regiones de plantilla, como me ha ocurrido a mí con los archivos que he utilizado para las pruebas.

En todo caso, es preciso tener muy presente que la selección del contenido que hay que importar es una de las decisiones que tienen mayor influencia en la calidad del resultado final. Es imposible dar orientaciones fiables para todos los posibles casos, pero yo aconsejaría a quien quiera tener éxito en el proceso que analice cuidadosamente los ficheros HTML y observe si existe entre ellos un patrón coincidente que permita definir con precisión la etiqueta que hay que importar. Si no se puede determinar un patrón común (o varios patrones comunes para los respectivos lotes), habrá que importar la etiqueta <body>, pues es dicha etiqueta la que opera como contenedor de la información de un fichero HTML que resulta de interés para el proceso de importación.
El plugin permite una selección muy precisa de la etiqueta seleccionable (véanse los campos correspondientes a Tag, Attribute y Value), así como la limpieza del código HTML incorrecto (epígrafe Clean up bad (Word, Frontpage) HTML?). También da al usuario la posibilidad de seleccionar las etiquetas y atributos HTML permitidos, es decir, los que serán importados con éxito, una vez descartados todos los demás (campos Allowed HTML y Allowed atributes). Ahora bien, mi consejo es que, antes de dejar al plugin que se encargue de todo el trabajo de importación, es mejor “preparar” los archivos, lo cual ahorrará tiempo en el proceso y mejorará los resultados. A continuación, voy a explicar lo que he hecho para importar los archivos que forman parte de la sección de “Literatura y cine” de Lengua en Secundaria, sobre los que hecho las pruebas:
- Limpieza del código HTML que conforma la estructura de dichos archivos. Como estaban realizados con tablas, he eliminado todas las columnas, a excepción de la columna central, que es la que contiene el texto. Posteriormente, he convertido dicha columna en texto y he eliminado todo resto de formato tabular.
- Eliminación de las etiquetas correspondientes a los elementos que no se importarán. Es decir, etiquetas de scripts, de vínculos a hojas de estilo, de imágenes, etc. He conservado, no obstante, todo el material original (aprovecho para insistir en que siempre hay que trabajar con copias), para aprovecharlo posteriormente y hacer las necesarias comprobaciones entre el fichero origen y su traslación al blog.
- Depuración de todos los atributos “style”, “class” y similares. Es conveniente eliminar cualquier estilo o efecto CSS definido dentro de los archivos, pues el aspecto visual de las entradas y páginas, una vez importadas, depende de la plantilla elegida para el blog, que puede muy bien entrar en conflicto con dichos estilos. El código de los estilos sólo debería mantenerse si éstos se van a reproducir en la hoja CSS de la plantilla del blog (y ello con las cautelas necesarias, para evitar efectos indeseables).
- Limpieza de hipervínculos innecesarios. Por ejemplo, las páginas que yo he importado contienen notas a pie de página que no son reproducibles de forma directa en el blog (sí lo son con ayuda de plugins, como por ejemplo el WP-Footnotes), por lo que es mejor eliminar dichos elementos, y dejar sólo los números de las notas, a efectos de su posterior reproducción mediante los mecanismos que incorpora dicha extensión.
- Supresión de espacios innecesarios. Todo lo que sean dobles o triples espacios, sangrías, etc., se importará tal cual, por lo que conviene desprenderse de esta carga muerta.
¿Cómo realizar estas operaciones? Yo he utilizado el programa Dreamweaver (en su versión MX 2004, pues no dispongo de una edición más moderna, y la verdad es que tampoco la necesito), pues sus funciones de búsqueda y sustitución son, a mi modo de ver, inigualables por su flexibilidad y potencia. No he probado otras aplicaciones de edición HTML, pero supongo que se podrían conseguir resultados parecidos a los que he logrado yo, probablemente con más esfuerzo y tiempo de por medio.
3. Selección del título de los elementos importados
Éste es otro hito crucial en la importación de los archivos HTML. Como puede verse en la figura 3, el plugin presenta por defecto la opción más lógica y adecuada para la inmensa mayoría de los casos, que es la de elegir la etiqueta <title> para el título de la entrada o página (epígrafe Select title by), pero podría escogerse también una región de plantilla de Dreamweaver o cualquier otra etiqueta del código HTML, siempre que cuente con los atributos y valores adecuados. Incluso es posible depurar el título de cualquier elemento redundante, para lo cual habrá que introducir en el campo Phrase to remove from page title la información necesaria.

4. Selección de metadatos
El plugin hace posible la importación de los archivos HTML como páginas estáticas o entradas (véase la figura 4, campo Import files as). También se puede seleccionar la fecha con la que se crearán las entradas (campo Set timestamps to). Cabe importar los archivos a cualquiera de los estados de publicación que existen en WordPress (campo Set Status to), aunque yo aconsejo que se importen como borrador (“draft”), para disponer de la capacidad de editarlos posteriormente sin haber sido publicados. Por supuesto, los artículos del blog, una vez importados, se pueden atribuir a cualquiera de los usuarios definidos en la aplicación (campo Set author to).
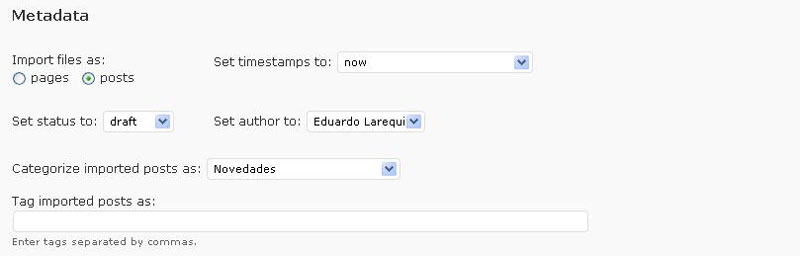
De gran importancia es la selección de la categoría a la que se van adjudicar las entradas, acción que hay que realizar desde el menú Categorize imported posts as (recuerdo que las categorías han de estar definidas antes de comenzar con la importación), así como la selección de las etiquetas o tags que hayan de ser adjudicadas a dichas entradas. Yo he preferido dejar este campo vacío, para poder etiquetar a posteriori, pero debe tenerse en cuenta que, si se opta por asignar etiquetas en el epígrafe Tag imported posts as, éstas se aplicarán a todos los ítems importados.
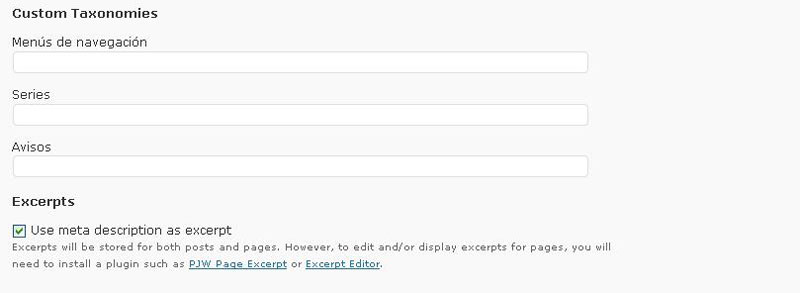
Es posible asignar a los archivos importados términos o etiquetas correspondientes a las taxonomías personalizadas que existan en el blog (véase la figura 5); ahora bien, como en el caso de las categorías, ello sólo es posible si dichas taxonomías han sido previamente definidas (subsección Custom Taxonomies). En cuanto a la última opción, relacionada con los extractos o resúmenes de los artículos (subsección Excerpts), el plugin hace posible utilizar los datos de las meta descripciones de los archivos HTML (la etiqueta <meta name=»description»> como resúmenes de los artículos del blog. Siempre que se disponga de dicha información en el material original, conviene activar la casilla Use meta description as excerpt.
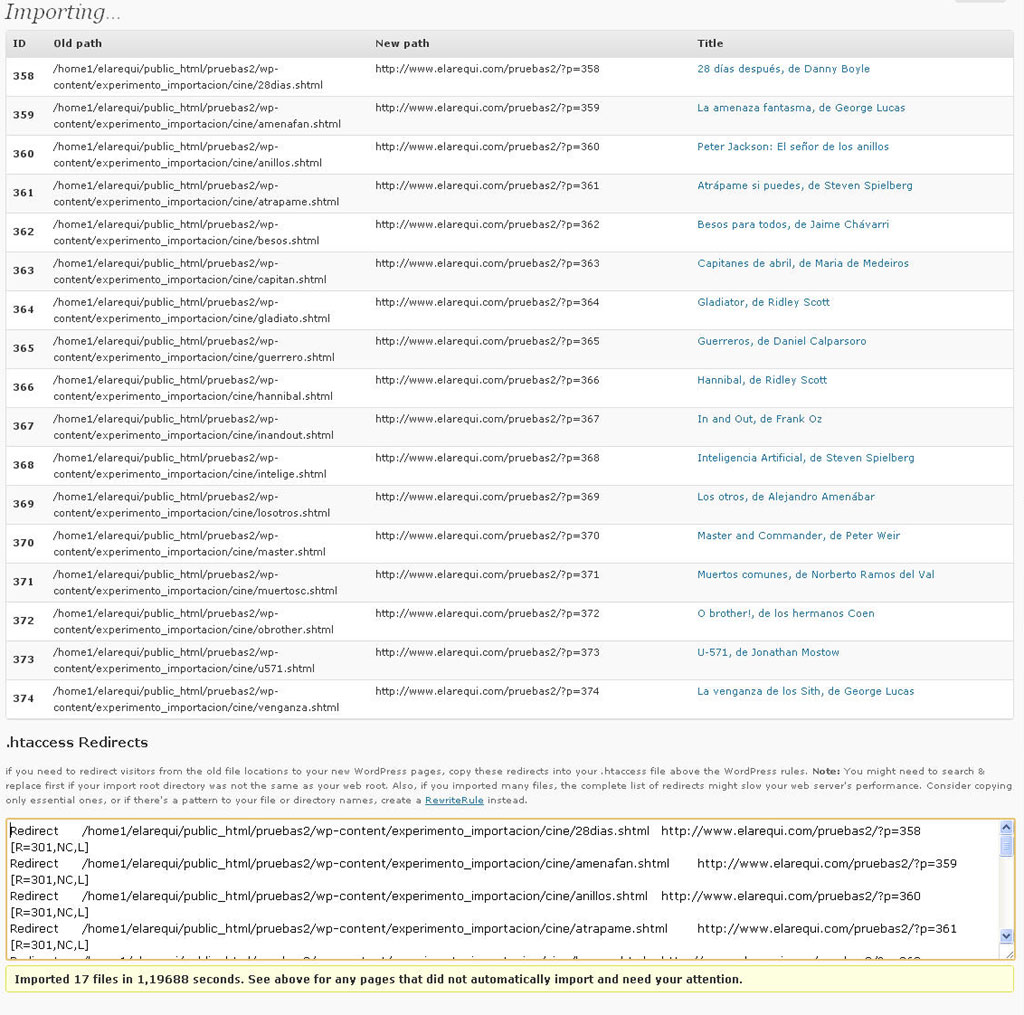
En las figuras 6 y 7 aparecen las capturas de pantalla correspondientes al blog de pruebas en el que yo he realizado mis experimentos de importación. Conviene aclarar que se trata de dos procesos de importación realizados sobre subdirectorios diferentes (/cine y /libros), a fin de poder diferenciar claramente las reseñas de películas y libros, adscritas a dos categorías diferentes: “Antiguas reseñas de libros” y “Antiguas reseñas de películas”, que he creado previamente con tal propósito. Obsérvese el tiempo dedicado a la importación, que ha sido francamente irrisorio: menos de 1,2 segundos para las diecisiete reseñas de películas, y todavía menos para otras tantas reseñas de libros. Buena prueba de la eficiencia del plugin y de la bondad del trabajo previo realizado para depurar el código HTML.
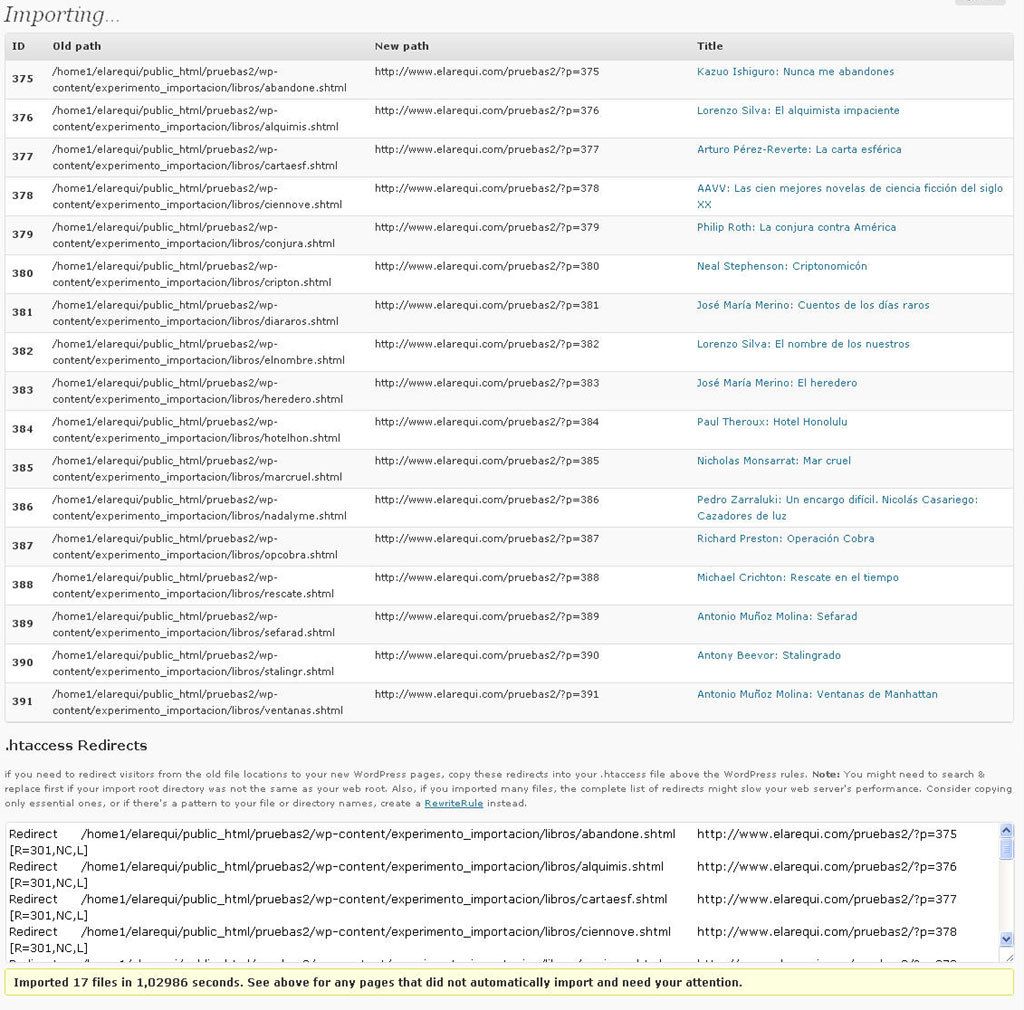
Por su parte, las figuras 8, 9 y 10 ilustran algunos detalles de uno de los archivos importados (la reseña de Stalingrado, de Antony Beevor), lo cual permite observar el resultado final, que es francamente bueno, aunque no impecable. Mis colegas blogueros más observadores podrán darse cuenta de varios fallos:
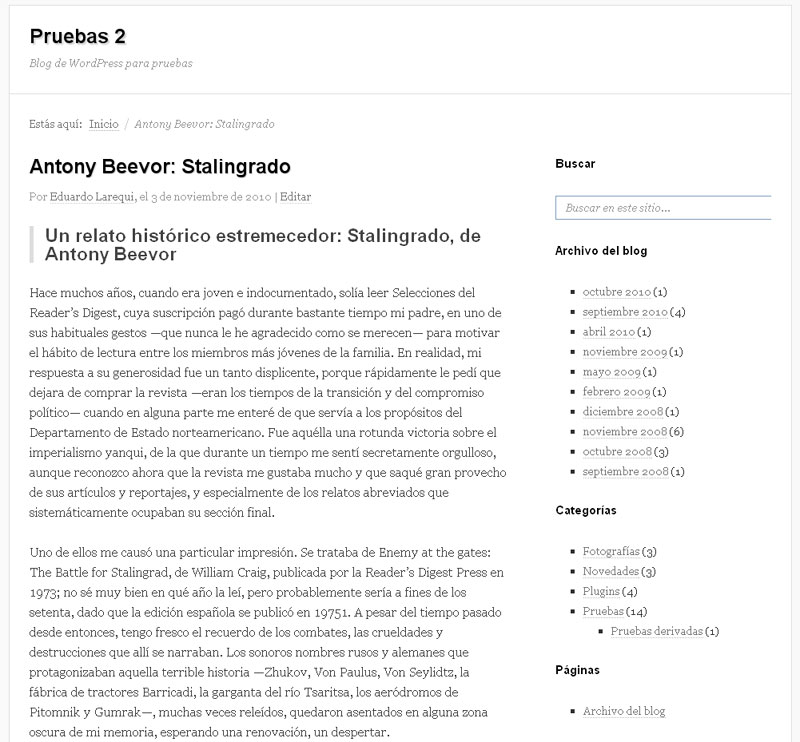


- El título de la reseña está repetido, porque se me olvidó eliminar del archivo HTML la etiqueta <h2> del título original.
- Han desaparecido las cursivas y negritas del texto original, por motivos que no alcanzo a comprender bien, pues las etiquetas <b> e <i> estaban incluidas en el listado de elementos HTML permitidos. Esta circunstancia obliga a una labor de repaso bastante irritante, por lo cual quizás merezca la pena borrar los artículos importados (se puede hacer a mano o, si se trata de una gran cantidad de artículos, utilizar un plugin como Mass Page Remover) y volver a realizar la importación, para ver si se repite el error.
- Hay algún párrafo vacío en el texto de la entrada. Esto ocurre porque dicho párrafo no fue detectado en el código HTML original, y por tanto no se realizó la correspondiente depuración.
En todo caso, estoy más que satisfecho con el resultado, sobre todo porque no hay nada que un atento proceso de revisión manual (siempre necesario y a mi modo de ver imprescindible en este tipo de operaciones) no pueda mejorar. Además, las pruebas realizadas demuestran, más allá de cualquier precisión o matiz, que el importador funciona perfectamente y puede ser la solución al objetivo expuesto al principio de este artículo. Quod erat demostrandum.
Actualización del 4 de noviembre de 2010
A fin de mejorar los resultados obtenidos en la primera prueba de importación, he borrado las entradas importadas y he vuelto a ejecutar el plugin de importación con algunas modificaciones, a saber:
- He editado los archivos originales para sustituir el contenido de la etiqueta strong><title> por el de <h2>, y luego he eliminado ésta. Así obtengo títulos idénticos a los originales de las reseñas, y consigo que, al importarse los archivos, las entradas resultantes no tengan el título repetido.
- He modificado los archivos HTML originales, sustituyendo las etiquetas <b> por <strong> e <i> por <em>. Con ello, las entradas importadas conservan las negritas y las cursivas.


[…] el plugin Import HTML Pages y llevé a cabo las operaciones necesarias para escribir el artículo Para convertir un sitio web estático en un blog. Con ello he conseguido matar dos pájaros de un tiro: por una parte, verificar el funcionamiento […]